API documentation¶
The following API documentation was automatically generated from the source code of humanfriendly 10.0:
- A note about backwards compatibility
humanfriendlyhumanfriendly.casehumanfriendly.clihumanfriendly.compathumanfriendly.decoratorshumanfriendly.deprecationhumanfriendly.promptshumanfriendly.sphinxhumanfriendly.tableshumanfriendly.terminalhumanfriendly.terminal.htmlhumanfriendly.terminal.spinnershumanfriendly.testinghumanfriendly.texthumanfriendly.usage
A note about backwards compatibility¶
The humanfriendly package started out as a single humanfriendly
module. Eventually this module grew to a size that necessitated splitting up
the code into multiple modules (see e.g. tables,
terminal, text and
usage). Most of the functionality that remains in the
humanfriendly module will eventually be moved to submodules as well (as
time permits and a logical subdivision of functionality presents itself to me).
While moving functionality around like this my goal is to always preserve backwards compatibility. For example if a function is moved to a submodule an import of that function is added in the main module so that backwards compatibility with previously written import statements is preserved.
If backwards compatibility of documented functionality has to be broken then the major version number will be bumped. So if you’re using the humanfriendly package in your project, make sure to at least pin the major version number in order to avoid unexpected surprises.
humanfriendly¶
The main module of the humanfriendly package.
Note
Deprecated names
The following aliases exist to preserve backwards compatibility, however a DeprecationWarning is triggered when they are accessed, because these aliases will be removed in a future release.
-
humanfriendly.compact¶ Alias for
humanfriendly.text.compact.
-
humanfriendly.concatenate¶ Alias for
humanfriendly.text.concatenate.
-
humanfriendly.format_table¶ Alias for
humanfriendly.tables.format_pretty_table.
-
humanfriendly.trim_empty_lines¶ Alias for
humanfriendly.text.trim_empty_lines.
-
humanfriendly.prompt_for_choice¶ Alias for
humanfriendly.prompts.prompt_for_choice.
-
humanfriendly.format¶ Alias for
humanfriendly.text.format.
-
humanfriendly.hide_cursor_code¶ Alias for
humanfriendly.terminal.ANSI_SHOW_CURSOR.
-
humanfriendly.Spinner¶ Alias for
humanfriendly.terminal.spinners.Spinner.
-
humanfriendly.minimum_spinner_interval¶
-
humanfriendly.dedent¶ Alias for
humanfriendly.text.dedent.
-
humanfriendly.show_cursor_code¶ Alias for
humanfriendly.terminal.ANSI_HIDE_CURSOR.
-
humanfriendly.tokenize¶ Alias for
humanfriendly.text.tokenize.
-
humanfriendly.AutomaticSpinner¶
-
humanfriendly.is_empty_line¶ Alias for
humanfriendly.text.is_empty_line.
-
humanfriendly.erase_line_code¶ Alias for
humanfriendly.terminal.ANSI_ERASE_LINE.
-
humanfriendly.pluralize¶ Alias for
humanfriendly.text.pluralize.
-
class
humanfriendly.SizeUnit(divider, symbol, name)¶ -
__getnewargs__()¶ Return self as a plain tuple. Used by copy and pickle.
-
__getstate__()¶ Exclude the OrderedDict from pickling
-
static
__new__(_cls, divider, symbol, name)¶ Create new instance of SizeUnit(divider, symbol, name)
-
__repr__()¶ Return a nicely formatted representation string
-
_asdict()¶ Return a new OrderedDict which maps field names to their values
-
classmethod
_make(iterable, new=<built-in method __new__ of type object>, len=<built-in function len>)¶ Make a new SizeUnit object from a sequence or iterable
-
_replace(**kwds)¶ Return a new SizeUnit object replacing specified fields with new values
-
divider¶ Alias for field number 0
-
name¶ Alias for field number 2
-
symbol¶ Alias for field number 1
-
-
class
humanfriendly.CombinedUnit(decimal, binary)¶ -
__getnewargs__()¶ Return self as a plain tuple. Used by copy and pickle.
-
__getstate__()¶ Exclude the OrderedDict from pickling
-
static
__new__(_cls, decimal, binary)¶ Create new instance of CombinedUnit(decimal, binary)
-
__repr__()¶ Return a nicely formatted representation string
-
_asdict()¶ Return a new OrderedDict which maps field names to their values
-
classmethod
_make(iterable, new=<built-in method __new__ of type object>, len=<built-in function len>)¶ Make a new CombinedUnit object from a sequence or iterable
-
_replace(**kwds)¶ Return a new CombinedUnit object replacing specified fields with new values
-
binary¶ Alias for field number 1
-
decimal¶ Alias for field number 0
-
-
humanfriendly.coerce_boolean(value)¶ Coerce any value to a boolean.
Parameters: value – Any Python value. If the value is a string:
- The strings ‘1’, ‘yes’, ‘true’ and ‘on’ are coerced to
True. - The strings ‘0’, ‘no’, ‘false’ and ‘off’ are coerced to
False. - Other strings raise an exception.
Other Python values are coerced using
bool.Returns: A proper boolean value. Raises: exceptions.ValueErrorwhen the value is a string but cannot be coerced with certainty.- The strings ‘1’, ‘yes’, ‘true’ and ‘on’ are coerced to
-
humanfriendly.coerce_pattern(value, flags=0)¶ Coerce strings to compiled regular expressions.
Parameters: - value – A string containing a regular expression pattern or a compiled regular expression.
- flags – The flags used to compile the pattern (an integer).
Returns: A compiled regular expression.
Raises: ValueErrorwhen value isn’t a string and also isn’t a compiled regular expression.
-
humanfriendly.coerce_seconds(value)¶ Coerce a value to the number of seconds.
Parameters: value – An int,floatordatetime.timedeltaobject.Returns: An intorfloatvalue.When value is a
datetime.timedeltaobject thetotal_seconds()method is called.
-
humanfriendly.format_size(num_bytes, keep_width=False, binary=False)¶ Format a byte count as a human readable file size.
Parameters: Returns: The corresponding human readable file size (a string).
This function knows how to format sizes in bytes, kilobytes, megabytes, gigabytes, terabytes and petabytes. Some examples:
>>> from humanfriendly import format_size >>> format_size(0) '0 bytes' >>> format_size(1) '1 byte' >>> format_size(5) '5 bytes' > format_size(1000) '1 KB' > format_size(1024, binary=True) '1 KiB' >>> format_size(1000 ** 3 * 4) '4 GB'
-
humanfriendly.parse_size(size, binary=False)¶ Parse a human readable data size and return the number of bytes.
Parameters: Returns: The corresponding size in bytes (an integer).
Raises: InvalidSizewhen the input can’t be parsed.This function knows how to parse sizes in bytes, kilobytes, megabytes, gigabytes, terabytes and petabytes. Some examples:
>>> from humanfriendly import parse_size >>> parse_size('42') 42 >>> parse_size('13b') 13 >>> parse_size('5 bytes') 5 >>> parse_size('1 KB') 1000 >>> parse_size('1 kilobyte') 1000 >>> parse_size('1 KiB') 1024 >>> parse_size('1 KB', binary=True) 1024 >>> parse_size('1.5 GB') 1500000000 >>> parse_size('1.5 GB', binary=True) 1610612736
-
humanfriendly.format_length(num_metres, keep_width=False)¶ Format a metre count as a human readable length.
Parameters: Returns: The corresponding human readable length (a string).
This function supports ranges from nanometres to kilometres.
Some examples:
>>> from humanfriendly import format_length >>> format_length(0) '0 metres' >>> format_length(1) '1 metre' >>> format_length(5) '5 metres' >>> format_length(1000) '1 km' >>> format_length(0.004) '4 mm'
-
humanfriendly.parse_length(length)¶ Parse a human readable length and return the number of metres.
Parameters: length – The human readable length to parse (a string). Returns: The corresponding length in metres (a float). Raises: InvalidLengthwhen the input can’t be parsed.Some examples:
>>> from humanfriendly import parse_length >>> parse_length('42') 42 >>> parse_length('1 km') 1000 >>> parse_length('5mm') 0.005 >>> parse_length('15.3cm') 0.153
-
humanfriendly.format_number(number, num_decimals=2)¶ Format a number as a string including thousands separators.
Parameters: Returns: The formatted number (a string).
This function is intended to make it easier to recognize the order of size of the number being formatted.
Here’s an example:
>>> from humanfriendly import format_number >>> print(format_number(6000000)) 6,000,000 > print(format_number(6000000000.42)) 6,000,000,000.42 > print(format_number(6000000000.42, num_decimals=0)) 6,000,000,000
-
humanfriendly.round_number(count, keep_width=False)¶ Round a floating point number to two decimal places in a human friendly format.
Parameters: Returns: The formatted number as a string. If no decimal places are required to represent the number, they will be omitted.
The main purpose of this function is to be used by functions like
format_length(),format_size()andformat_timespan().Here are some examples:
>>> from humanfriendly import round_number >>> round_number(1) '1' >>> round_number(math.pi) '3.14' >>> round_number(5.001) '5'
-
humanfriendly.format_timespan(num_seconds, detailed=False, max_units=3)¶ Format a timespan in seconds as a human readable string.
Parameters: - num_seconds – Any value accepted by
coerce_seconds(). - detailed – If
Truemilliseconds are represented separately instead of being represented as fractional seconds (defaults toFalse). - max_units – The maximum number of units to show in the formatted time span (an integer, defaults to three).
Returns: The formatted timespan as a string.
Raise: See
coerce_seconds().Some examples:
>>> from humanfriendly import format_timespan >>> format_timespan(0) '0 seconds' >>> format_timespan(1) '1 second' >>> import math >>> format_timespan(math.pi) '3.14 seconds' >>> hour = 60 * 60 >>> day = hour * 24 >>> week = day * 7 >>> format_timespan(week * 52 + day * 2 + hour * 3) '1 year, 2 days and 3 hours'
- num_seconds – Any value accepted by
-
humanfriendly.parse_timespan(timespan)¶ Parse a “human friendly” timespan into the number of seconds.
Parameters: value – A string like 5h(5 hours),10m(10 minutes) or42s(42 seconds).Returns: The number of seconds as a floating point number. Raises: InvalidTimespanwhen the input can’t be parsed.Note that the
parse_timespan()function is not meant to be the “mirror image” of theformat_timespan()function. Instead it’s meant to allow humans to easily and succinctly specify a timespan with a minimal amount of typing. It’s very useful to accept easy to write time spans as e.g. command line arguments to programs.The time units (and abbreviations) supported by this function are:
- ms, millisecond, milliseconds
- s, sec, secs, second, seconds
- m, min, mins, minute, minutes
- h, hour, hours
- d, day, days
- w, week, weeks
- y, year, years
Some examples:
>>> from humanfriendly import parse_timespan >>> parse_timespan('42') 42.0 >>> parse_timespan('42s') 42.0 >>> parse_timespan('1m') 60.0 >>> parse_timespan('1h') 3600.0 >>> parse_timespan('1d') 86400.0
-
humanfriendly.parse_date(datestring)¶ Parse a date/time string into a tuple of integers.
Parameters: datestring – The date/time string to parse. Returns: A tuple with the numbers (year, month, day, hour, minute, second)(all numbers are integers).Raises: InvalidDatewhen the date cannot be parsed.Supported date/time formats:
YYYY-MM-DDYYYY-MM-DD HH:MM:SS
Note
If you want to parse date/time strings with a fixed, known format and
parse_date()isn’t useful to you, considertime.strptime()ordatetime.datetime.strptime(), both of which are included in the Python standard library. Alternatively for more complex tasks consider using the date/time parsing module in the dateutil package.Examples:
>>> from humanfriendly import parse_date >>> parse_date('2013-06-17') (2013, 6, 17, 0, 0, 0) >>> parse_date('2013-06-17 02:47:42') (2013, 6, 17, 2, 47, 42)
Here’s how you convert the result to a number (Unix time):
>>> from humanfriendly import parse_date >>> from time import mktime >>> mktime(parse_date('2013-06-17 02:47:42') + (-1, -1, -1)) 1371430062.0
And here’s how you convert it to a
datetime.datetimeobject:>>> from humanfriendly import parse_date >>> from datetime import datetime >>> datetime(*parse_date('2013-06-17 02:47:42')) datetime.datetime(2013, 6, 17, 2, 47, 42)
Here’s an example that combines
format_timespan()andparse_date()to calculate a human friendly timespan since a given date:>>> from humanfriendly import format_timespan, parse_date >>> from time import mktime, time >>> unix_time = mktime(parse_date('2013-06-17 02:47:42') + (-1, -1, -1)) >>> seconds_since_then = time() - unix_time >>> print(format_timespan(seconds_since_then)) 1 year, 43 weeks and 1 day
-
humanfriendly.format_path(pathname)¶ Shorten a pathname to make it more human friendly.
Parameters: pathname – An absolute pathname (a string). Returns: The pathname with the user’s home directory abbreviated. Given an absolute pathname, this function abbreviates the user’s home directory to
~/in order to shorten the pathname without losing information. It is not an error if the pathname is not relative to the current user’s home directory.Here’s an example of its usage:
>>> from os import environ >>> from os.path import join >>> vimrc = join(environ['HOME'], '.vimrc') >>> vimrc '/home/peter/.vimrc' >>> from humanfriendly import format_path >>> format_path(vimrc) '~/.vimrc'
-
humanfriendly.parse_path(pathname)¶ Convert a human friendly pathname to an absolute pathname.
Expands leading tildes using
os.path.expanduser()and environment variables usingos.path.expandvars()and makes the resulting pathname absolute usingos.path.abspath().Parameters: pathname – A human friendly pathname (a string). Returns: An absolute pathname (a string).
-
class
humanfriendly.Timer(start_time=None, resumable=False)¶ Easy to use timer to keep track of long during operations.
-
__init__(start_time=None, resumable=False)¶ Remember the time when the
Timerwas created.Parameters: - start_time – The start time (a float, defaults to the current time).
- resumable – Create a resumable timer (defaults to
False).
When start_time is given
Timerusestime.time()as a clock source, otherwise it useshumanfriendly.compat.monotonic().
-
__enter__()¶ Start or resume counting elapsed time.
Returns: The Timerobject.Raises: ValueErrorwhen the timer isn’t resumable.
-
__exit__(exc_type=None, exc_value=None, traceback=None)¶ Stop counting elapsed time.
Raises: ValueErrorwhen the timer isn’t resumable.
-
sleep(seconds)¶ Easy to use rate limiting of repeating actions.
Parameters: seconds – The number of seconds to sleep (an integer or floating point number). This method sleeps for the given number of seconds minus the
elapsed_time. If the resulting duration is negativetime.sleep()will still be called, but the argument given to it will be the number 0 (negative numbers causetime.sleep()to raise an exception).The use case for this is to initialize a
Timerinside the body of afororwhileloop and callTimer.sleep()at the end of the loop body to rate limit whatever it is that is being done inside the loop body.For posterity: Although the implementation of
sleep()only requires a single line of code I’ve added it tohumanfriendlyanyway because now that I’ve thought about how to tackle this once I never want to have to think about it again :-P (unless I find ways to improve this).
-
elapsed_time¶ Get the number of seconds counted so far.
-
rounded¶ Human readable timespan rounded to seconds (a string).
-
-
exception
humanfriendly.InvalidDate¶ Raised when a string cannot be parsed into a date.
For example:
>>> from humanfriendly import parse_date >>> parse_date('2013-06-XY') Traceback (most recent call last): File "humanfriendly.py", line 206, in parse_date raise InvalidDate(format(msg, datestring)) humanfriendly.InvalidDate: Invalid date! (expected 'YYYY-MM-DD' or 'YYYY-MM-DD HH:MM:SS' but got: '2013-06-XY')
-
exception
humanfriendly.InvalidSize¶ Raised when a string cannot be parsed into a file size.
For example:
>>> from humanfriendly import parse_size >>> parse_size('5 Z') Traceback (most recent call last): File "humanfriendly/__init__.py", line 267, in parse_size raise InvalidSize(format(msg, size, tokens)) humanfriendly.InvalidSize: Failed to parse size! (input '5 Z' was tokenized as [5, 'Z'])
-
exception
humanfriendly.InvalidLength¶ Raised when a string cannot be parsed into a length.
For example:
>>> from humanfriendly import parse_length >>> parse_length('5 Z') Traceback (most recent call last): File "humanfriendly/__init__.py", line 267, in parse_length raise InvalidLength(format(msg, length, tokens)) humanfriendly.InvalidLength: Failed to parse length! (input '5 Z' was tokenized as [5, 'Z'])
-
exception
humanfriendly.InvalidTimespan¶ Raised when a string cannot be parsed into a timespan.
For example:
>>> from humanfriendly import parse_timespan >>> parse_timespan('1 age') Traceback (most recent call last): File "humanfriendly/__init__.py", line 419, in parse_timespan raise InvalidTimespan(format(msg, timespan, tokens)) humanfriendly.InvalidTimespan: Failed to parse timespan! (input '1 age' was tokenized as [1, 'age'])
humanfriendly.case¶
Simple case insensitive dictionaries.
The CaseInsensitiveDict class is a dictionary whose string keys
are case insensitive. It works by automatically coercing string keys to
CaseInsensitiveKey objects. Keys that are not strings are
supported as well, just without case insensitivity.
At its core this module works by normalizing strings to lowercase before comparing or hashing them. It doesn’t support proper case folding nor does it support Unicode normalization, hence the word “simple”.
-
class
humanfriendly.case.CaseInsensitiveDict(other=None, **kw)¶ Simple case insensitive dictionary implementation (that remembers insertion order).
This class works by overriding methods that deal with dictionary keys to coerce string keys to
CaseInsensitiveKeyobjects before calling down to the regular dictionary handling methods. While intended to be complete this class has not been extensively tested yet.-
__init__(other=None, **kw)¶ Initialize a
CaseInsensitiveDictobject.
-
coerce_key(key)¶ Coerce string keys to
CaseInsensitiveKeyobjects.Parameters: key – The value to coerce (any type). Returns: If key is a string then a CaseInsensitiveKeyobject is returned, otherwise the value of key is returned unmodified.
-
classmethod
fromkeys(iterable, value=None)¶ Create a case insensitive dictionary with keys from iterable and values set to value.
-
get(key, default=None)¶ Get the value of an existing item.
-
pop(key, default=None)¶ Remove an item from a case insensitive dictionary.
-
setdefault(key, default=None)¶ Get the value of an existing item or add a new item.
-
update(other=None, **kw)¶ Update a case insensitive dictionary with new items.
-
__contains__(key)¶ Check if a case insensitive dictionary contains the given key.
-
__delitem__(key)¶ Delete an item in a case insensitive dictionary.
-
__getitem__(key)¶ Get the value of an item in a case insensitive dictionary.
-
__setitem__(key, value)¶ Set the value of an item in a case insensitive dictionary.
-
-
class
humanfriendly.case.CaseInsensitiveKey¶ Simple case insensitive dictionary key implementation.
The
CaseInsensitiveKeyclass provides an intentionally simple implementation of case insensitive strings to be used as dictionary keys.If you need features like Unicode normalization or proper case folding please consider using a more advanced implementation like the istr package instead.
-
static
__new__(cls, value)¶ Create a
CaseInsensitiveKeyobject.
-
__hash__()¶ Get the hash value of the lowercased string.
-
__eq__(other)¶ Compare two strings as lowercase.
-
static
humanfriendly.cli¶
Usage: humanfriendly [OPTIONS]
Human friendly input/output (text formatting) on the command line based on the Python package with the same name.
Supported options:
| Option | Description |
|---|---|
-c, --run-command |
Execute an external command (given as the positional arguments) and render a spinner and timer while the command is running. The exit status of the command is propagated. |
--format-table |
Read tabular data from standard input (each line is a row and each
whitespace separated field is a column), format the data as a table and
print the resulting table to standard output. See also the --delimiter
option. |
-d, --delimiter=VALUE |
Change the delimiter used by --format-table to VALUE (a string). By default
all whitespace is treated as a delimiter. |
-l, --format-length=LENGTH |
Convert a length count (given as the integer or float LENGTH) into a human
readable string and print that string to standard output. |
-n, --format-number=VALUE |
Format a number (given as the integer or floating point number VALUE) with
thousands separators and two decimal places (if needed) and print the
formatted number to standard output. |
-s, --format-size=BYTES |
Convert a byte count (given as the integer BYTES) into a human readable
string and print that string to standard output. |
-b, --binary |
Change the output of -s, --format-size to use binary multiples of bytes
(base-2) instead of the default decimal multiples of bytes (base-10). |
-t, --format-timespan=SECONDS |
Convert a number of seconds (given as the floating point number SECONDS)
into a human readable timespan and print that string to standard output. |
--parse-length=VALUE |
Parse a human readable length (given as the string VALUE) and print the
number of metres to standard output. |
--parse-size=VALUE |
Parse a human readable data size (given as the string VALUE) and print the
number of bytes to standard output. |
--demo |
Demonstrate changing the style and color of the terminal font using ANSI escape sequences. |
-h, --help |
Show this message and exit. |
-
humanfriendly.cli.main()¶ Command line interface for the
humanfriendlyprogram.
-
humanfriendly.cli.run_command(command_line)¶ Run an external command and show a spinner while the command is running.
-
humanfriendly.cli.print_formatted_length(value)¶ Print a human readable length.
-
humanfriendly.cli.print_formatted_number(value)¶ Print large numbers in a human readable format.
-
humanfriendly.cli.print_formatted_size(value, binary)¶ Print a human readable size.
-
humanfriendly.cli.print_formatted_table(delimiter)¶ Read tabular data from standard input and print a table.
-
humanfriendly.cli.print_formatted_timespan(value)¶ Print a human readable timespan.
-
humanfriendly.cli.print_parsed_length(value)¶ Parse a human readable length and print the number of metres.
-
humanfriendly.cli.print_parsed_size(value)¶ Parse a human readable data size and print the number of bytes.
-
humanfriendly.cli.demonstrate_ansi_formatting()¶ Demonstrate the use of ANSI escape sequences.
-
humanfriendly.cli.demonstrate_256_colors(i, j, group=None)¶ Demonstrate 256 color mode support.
humanfriendly.compat¶
Compatibility with Python 2 and 3.
This module exposes aliases and functions that make it easier to write Python code that is compatible with Python 2 and Python 3.
-
humanfriendly.compat.basestring¶ Alias for
basestring()(in Python 2) orstr(in Python 3). See alsois_string().
-
humanfriendly.compat.HTMLParser¶ Alias for
HTMLParser.HTMLParser(in Python 2) orhtml.parser.HTMLParser(in Python 3).
-
humanfriendly.compat.interactive_prompt¶ Alias for
raw_input()(in Python 2) orinput()(in Python 3).
-
humanfriendly.compat.StringIO¶ Alias for
StringIO.StringIO(in Python 2) orio.StringIO(in Python 3).
-
humanfriendly.compat.unicode¶ Alias for
unicode()(in Python 2) orstr(in Python 3). See alsocoerce_string().
-
humanfriendly.compat.monotonic¶ Alias for
time.monotonic()(in Python 3.3 and higher) or monotonic.monotonic() (a conditional dependency on older Python versions).
-
humanfriendly.compat.coerce_string(value)¶ Coerce any value to a Unicode string (
unicode()in Python 2 andstrin Python 3).Parameters: value – The value to coerce. Returns: The value coerced to a Unicode string.
-
humanfriendly.compat.is_string(value)¶ Check if a value is a
basestring()(in Python 2) orstr(in Python 3) object.Parameters: value – The value to check. Returns: Trueif the value is a string,Falseotherwise.
-
humanfriendly.compat.is_unicode(value)¶ Check if a value is a
unicode()(in Python 2) orstr(in Python 3) object.Parameters: value – The value to check. Returns: Trueif the value is a Unicode string,Falseotherwise.
humanfriendly.decorators¶
Simple function decorators to make Python programming easier.
-
humanfriendly.decorators.RESULTS_ATTRIBUTE= 'cached_results'¶ The name of the property used to cache the return values of functions (a string).
-
humanfriendly.decorators.cached(function)¶ Rudimentary caching decorator for functions.
Parameters: function – The function whose return value should be cached. Returns: The decorated function. The given function will only be called once, the first time the wrapper function is called. The return value is cached by the wrapper function as an attribute of the given function and returned on each subsequent call.
Note
Currently no function arguments are supported because only a single return value can be cached. Accepting any function arguments at all would imply that the cache is parametrized on function arguments, which is not currently the case.
humanfriendly.deprecation¶
Support for deprecation warnings when importing names from old locations.
When software evolves, things tend to move around. This is usually detrimental
to backwards compatibility (in Python this primarily manifests itself as
ImportError exceptions).
While backwards compatibility is very important, it should not get in the way of progress. It would be great to have the agility to move things around without breaking backwards compatibility.
This is where the humanfriendly.deprecation module comes in: It enables
the definition of backwards compatible aliases that emit a deprecation warning
when they are accessed.
The way it works is that it wraps the original module in an DeprecationProxy
object that defines a __getattr__() special method to
override attribute access of the module.
-
humanfriendly.deprecation.define_aliases(module_name, **aliases)¶ Update a module with backwards compatible aliases.
Parameters: - module_name – The
__name__of the module (a string). - aliases – Each keyword argument defines an alias. The values are expected to be “dotted paths” (strings).
The behavior of this function depends on whether the Sphinx documentation generator is active, because the use of
DeprecationProxyto shadow the real module insys.moduleshas the unintended side effect of breaking autodoc support for:data:members (module variables).To avoid breaking Sphinx the proxy object is omitted and instead the aliased names are injected into the original module namespace, to make sure that imports can be satisfied when the documentation is being rendered.
If you run into cyclic dependencies caused by
define_aliases()when running Sphinx, you can try moving the call todefine_aliases()to the bottom of the Python module you’re working on.- module_name – The
-
humanfriendly.deprecation.get_aliases(module_name)¶ Get the aliases defined by a module.
Parameters: module_name – The __name__of the module (a string).Returns: A dictionary with string keys and values: - Each key gives the name of an alias created for backwards compatibility.
- Each value gives the dotted path of the proper location of the identifier.
An empty dictionary is returned for modules that don’t define any backwards compatible aliases.
-
humanfriendly.deprecation.deprecated_args(*names)¶ Deprecate positional arguments without dropping backwards compatibility.
Parameters: names – The positional arguments to deprecated_args()give the names of the positional arguments that the to-be-decorated function should warn about being deprecated and translate to keyword arguments.Returns: A decorator function specialized to names. The
deprecated_args()decorator function was created to make it easy to switch from positional arguments to keyword arguments [1] while preserving backwards compatibility [2] and informing call sites about the change.[1] Increased flexibility is the main reason why I find myself switching from positional arguments to (optional) keyword arguments as my code evolves to support more use cases. [2] In my experience positional argument order implicitly becomes part of API compatibility whether intended or not. While this makes sense for functions that over time adopt more and more optional arguments, at a certain point it becomes an inconvenience to code maintenance. Here’s an example of how to use the decorator:
@deprecated_args('text') def report_choice(**options): print(options['text'])
When the decorated function is called with positional arguments a deprecation warning is given:
>>> report_choice('this will give a deprecation warning') DeprecationWarning: report_choice has deprecated positional arguments, please switch to keyword arguments this will give a deprecation warning
But when the function is called with keyword arguments no deprecation warning is emitted:
>>> report_choice(text='this will not give a deprecation warning') this will not give a deprecation warning
-
humanfriendly.deprecation.is_method(function)¶ Check if the expected usage of the given function is as an instance method.
-
class
humanfriendly.deprecation.DeprecationProxy(module, aliases)¶ Emit deprecation warnings for imports that should be updated.
-
__init__(module, aliases)¶ Initialize an
DeprecationProxyobject.Parameters: - module – The original module object.
- aliases – A dictionary of aliases.
-
__getattr__(name)¶ Override module attribute lookup.
Parameters: name – The name to look up (a string). Returns: The attribute value.
-
resolve(target)¶ Look up the target of an alias.
Parameters: target – The fully qualified dotted path (a string). Returns: The value of the given target.
-
humanfriendly.prompts¶
Interactive terminal prompts.
The prompts module enables interaction with the user
(operator) by asking for confirmation (prompt_for_confirmation()) and
asking to choose from a list of options (prompt_for_choice()). It works
by rendering interactive prompts on the terminal.
-
humanfriendly.prompts.MAX_ATTEMPTS= 10¶ The number of times an interactive prompt is shown on invalid input (an integer).
-
humanfriendly.prompts.prompt_for_confirmation(question, default=None, padding=True)¶ Prompt the user for confirmation.
Parameters: - question – The text that explains what the user is confirming (a string).
- default – The default value (a boolean) or
None. - padding – Refer to the documentation of
prompt_for_input().
Returns: - If the user enters ‘yes’ or ‘y’ then
Trueis returned. - If the user enters ‘no’ or ‘n’ then
Falseis returned. - If the user doesn’t enter any text or standard input is not
connected to a terminal (which makes it impossible to prompt
the user) the value of the keyword argument
defaultis returned (if that value is notNone).
Raises: - Any exceptions raised by
retry_limit(). - Any exceptions raised by
prompt_for_input().
When default is
Falseand the user doesn’t enter any text an error message is printed and the prompt is repeated:>>> prompt_for_confirmation("Are you sure?") <BLANKLINE> Are you sure? [y/n] <BLANKLINE> Error: Please enter 'yes' or 'no' (there's no default choice). <BLANKLINE> Are you sure? [y/n]
The same thing happens when the user enters text that isn’t recognized:
>>> prompt_for_confirmation("Are you sure?") <BLANKLINE> Are you sure? [y/n] about what? <BLANKLINE> Error: Please enter 'yes' or 'no' (the text 'about what?' is not recognized). <BLANKLINE> Are you sure? [y/n]
-
humanfriendly.prompts.prompt_for_choice(choices, default=None, padding=True)¶ Prompt the user to select a choice from a group of options.
Parameters: - choices – A sequence of strings with available options.
- default – The default choice if the user simply presses Enter
(expected to be a string, defaults to
None). - padding – Refer to the documentation of
prompt_for_input().
Returns: The string corresponding to the user’s choice.
Raises: ValueErrorif choices is an empty sequence.- Any exceptions raised by
retry_limit(). - Any exceptions raised by
prompt_for_input().
When no options are given an exception is raised:
>>> prompt_for_choice([]) Traceback (most recent call last): File "humanfriendly/prompts.py", line 148, in prompt_for_choice raise ValueError("Can't prompt for choice without any options!") ValueError: Can't prompt for choice without any options!
If a single option is given the user isn’t prompted:
>>> prompt_for_choice(['only one choice']) 'only one choice'
Here’s what the actual prompt looks like by default:
>>> prompt_for_choice(['first option', 'second option']) <BLANKLINE> 1. first option 2. second option <BLANKLINE> Enter your choice as a number or unique substring (Control-C aborts): second <BLANKLINE> 'second option'
If you don’t like the whitespace (empty lines and indentation):
>>> prompt_for_choice(['first option', 'second option'], padding=False) 1. first option 2. second option Enter your choice as a number or unique substring (Control-C aborts): first 'first option'
-
humanfriendly.prompts.prompt_for_input(question, default=None, padding=True, strip=True)¶ Prompt the user for input (free form text).
Parameters: - question – An explanation of what is expected from the user (a string).
- default – The return value if the user doesn’t enter any text or standard input is not connected to a terminal (which makes it impossible to prompt the user).
- padding – Render empty lines before and after the prompt to make it
stand out from the surrounding text? (a boolean, defaults
to
True) - strip – Strip leading/trailing whitespace from the user’s reply?
Returns: The text entered by the user (a string) or the value of the default argument.
Raises: KeyboardInterruptwhen the program is interrupted while the prompt is active, for example because the user presses Control-C.EOFErrorwhen reading from standard input fails, for example because the user presses Control-D or because the standard input stream is redirected (only if default isNone).
-
humanfriendly.prompts.prepare_prompt_text(prompt_text, **options)¶ Wrap a text to be rendered as an interactive prompt in ANSI escape sequences.
Parameters: - prompt_text – The text to render on the prompt (a string).
- options – Any keyword arguments are passed on to
ansi_wrap().
Returns: The resulting prompt text (a string).
ANSI escape sequences are only used when the standard output stream is connected to a terminal. When the standard input stream is connected to a terminal any escape sequences are wrapped in “readline hints”.
-
humanfriendly.prompts.prepare_friendly_prompts()¶ Make interactive prompts more user friendly.
The prompts presented by
raw_input()(in Python 2) andinput()(in Python 3) are not very user friendly by default, for example the cursor keys (←, ↑, → and ↓) and the Home and End keys enter characters instead of performing the action you would expect them to. By simply importing thereadlinemodule these prompts become much friendlier (as mentioned in the Python standard library documentation).This function is called by the other functions in this module to enable user friendly prompts.
-
humanfriendly.prompts.retry_limit(limit=10)¶ Allow the user to provide valid input up to limit times.
Parameters: limit – The maximum number of attempts (a number, defaults to MAX_ATTEMPTS).Returns: A generator of numbers starting from one. Raises: TooManyInvalidReplieswhen an interactive prompt receives repeated invalid input (MAX_ATTEMPTS).This function returns a generator for interactive prompts that want to repeat on invalid input without getting stuck in infinite loops.
-
exception
humanfriendly.prompts.TooManyInvalidReplies¶ Raised by interactive prompts when they’ve received too many invalid inputs.
humanfriendly.sphinx¶
Customizations for and integration with the Sphinx documentation generator.
The humanfriendly.sphinx module uses the Sphinx extension API to
customize the process of generating Sphinx based Python documentation. To
explore the functionality this module offers its best to start reading
from the setup() function.
-
humanfriendly.sphinx.deprecation_note_callback(app, what, name, obj, options, lines)¶ Automatically document aliases defined using
define_aliases().Refer to
enable_deprecation_notes()to enable the use of this function (you probably don’t want to calldeprecation_note_callback()directly).This function implements a callback for
autodoc-process-docstringthat reformats module docstrings to append an overview of aliases defined by the module.The parameters expected by this function are those defined for Sphinx event callback functions (i.e. I’m not going to document them here :-).
-
humanfriendly.sphinx.enable_deprecation_notes(app)¶ Enable documenting backwards compatibility aliases using the autodoc extension.
Parameters: app – The Sphinx application object. This function connects the
deprecation_note_callback()function toautodoc-process-docstringevents.
-
humanfriendly.sphinx.enable_man_role(app)¶ Enable the
:man:role for linking to Debian Linux manual pages.Parameters: app – The Sphinx application object. This function registers the
man_role()function to handle the:man:role.
-
humanfriendly.sphinx.enable_pypi_role(app)¶ Enable the
:pypi:role for linking to the Python Package Index.Parameters: app – The Sphinx application object. This function registers the
pypi_role()function to handle the:pypi:role.
-
humanfriendly.sphinx.enable_special_methods(app)¶ Enable documenting “special methods” using the autodoc extension.
Parameters: app – The Sphinx application object. This function connects the
special_methods_callback()function toautodoc-skip-memberevents.
-
humanfriendly.sphinx.enable_usage_formatting(app)¶ Reformat human friendly usage messages to reStructuredText.
Parameters: app – The Sphinx application object (as given to setup()).This function connects the
usage_message_callback()function toautodoc-process-docstringevents.
-
humanfriendly.sphinx.man_role(role, rawtext, text, lineno, inliner, options={}, content=[])¶ Convert a Linux manual topic to a hyperlink.
Using the
:man:role is very simple, here’s an example:See the :man:`python` documentation.
This results in the following:
See the python documentation.As the example shows you can use the role inline, embedded in sentences of text. In the generated documentation the
:man:text is omitted and a hyperlink pointing to the Debian Linux manual pages is emitted.
-
humanfriendly.sphinx.pypi_role(role, rawtext, text, lineno, inliner, options={}, content=[])¶ Generate hyperlinks to the Python Package Index.
Using the
:pypi:role is very simple, here’s an example:See the :pypi:`humanfriendly` package.
This results in the following:
See the humanfriendly package.As the example shows you can use the role inline, embedded in sentences of text. In the generated documentation the
:pypi:text is omitted and a hyperlink pointing to the Python Package Index is emitted.
-
humanfriendly.sphinx.setup(app)¶ Enable all of the provided Sphinx customizations.
Parameters: app – The Sphinx application object. The
setup()function makes it easy to enable all of the Sphinx customizations provided by thehumanfriendly.sphinxmodule with the least amount of code. All you need to do is to add the module name to theextensionsvariable in yourconf.pyfile:# Sphinx extension module names. extensions = [ 'sphinx.ext.autodoc', 'sphinx.ext.doctest', 'sphinx.ext.intersphinx', 'humanfriendly.sphinx', ]
When Sphinx sees the
humanfriendly.sphinxname it will import the module and call itssetup()function. This function will then call the following:enable_deprecation_notes()enable_man_role()enable_pypi_role()enable_special_methods()enable_usage_formatting()
Of course more functionality may be added at a later stage. If you don’t like that idea you may be better of calling the individual functions from your own
setup()function.
-
humanfriendly.sphinx.special_methods_callback(app, what, name, obj, skip, options)¶ Enable documenting “special methods” using the autodoc extension.
Refer to
enable_special_methods()to enable the use of this function (you probably don’t want to callspecial_methods_callback()directly).This function implements a callback for
autodoc-skip-memberevents to include documented “special methods” (method names with two leading and two trailing underscores) in your documentation. The result is similar to the use of thespecial-membersflag with one big difference: Special methods are included but other types of members are ignored. This means that attributes like__weakref__will always be ignored (this was my main annoyance with thespecial-membersflag).The parameters expected by this function are those defined for Sphinx event callback functions (i.e. I’m not going to document them here :-).
-
humanfriendly.sphinx.usage_message_callback(app, what, name, obj, options, lines)¶ Reformat human friendly usage messages to reStructuredText.
Refer to
enable_usage_formatting()to enable the use of this function (you probably don’t want to callusage_message_callback()directly).This function implements a callback for
autodoc-process-docstringthat reformats module docstrings usingrender_usage()so that Sphinx doesn’t mangle usage messages that were written to be human readable instead of machine readable. Only module docstrings whose first line starts withUSAGE_MARKERare reformatted.The parameters expected by this function are those defined for Sphinx event callback functions (i.e. I’m not going to document them here :-).
humanfriendly.tables¶
Functions that render ASCII tables.
Some generic notes about the table formatting functions in this module:
- These functions were not written with performance in mind (at all) because they’re intended to format tabular data to be presented on a terminal. If someone were to run into a performance problem using these functions, they’d be printing so much tabular data to the terminal that a human wouldn’t be able to digest the tabular data anyway, so the point is moot :-).
- These functions ignore ANSI escape sequences (at least the ones generated by
the
terminalmodule) in the calculation of columns widths. On reason for this is that column names are highlighted in color when connected to a terminal. It also means that you can use ANSI escape sequences to highlight certain column’s values if you feel like it (for example to highlight deviations from the norm in an overview of calculated values).
-
humanfriendly.tables.format_smart_table(data, column_names)¶ Render tabular data using the most appropriate representation.
Parameters: Returns: The rendered table (a string).
If you want an easy way to render tabular data on a terminal in a human friendly format then this function is for you! It works as follows:
- If the input data doesn’t contain any line breaks the function
format_pretty_table()is used to render a pretty table. If the resulting table fits in the terminal without wrapping the rendered pretty table is returned. - If the input data does contain line breaks or if a pretty table would
wrap (given the width of the terminal) then the function
format_robust_table()is used to render a more robust table that can deal with data containing line breaks and long text.
- If the input data doesn’t contain any line breaks the function
-
humanfriendly.tables.format_pretty_table(data, column_names=None, horizontal_bar='-', vertical_bar='|')¶ Render a table using characters like dashes and vertical bars to emulate borders.
Parameters: - data – An iterable (e.g. a
tuple()orlist) containing the rows of the table, where each row is an iterable containing the columns of the table (strings). - column_names – An iterable of column names (strings).
- horizontal_bar – The character used to represent a horizontal bar (a string).
- vertical_bar – The character used to represent a vertical bar (a string).
Returns: The rendered table (a string).
Here’s an example:
>>> from humanfriendly.tables import format_pretty_table >>> column_names = ['Version', 'Uploaded on', 'Downloads'] >>> humanfriendly_releases = [ ... ['1.23', '2015-05-25', '218'], ... ['1.23.1', '2015-05-26', '1354'], ... ['1.24', '2015-05-26', '223'], ... ['1.25', '2015-05-26', '4319'], ... ['1.25.1', '2015-06-02', '197'], ... ] >>> print(format_pretty_table(humanfriendly_releases, column_names)) ------------------------------------- | Version | Uploaded on | Downloads | ------------------------------------- | 1.23 | 2015-05-25 | 218 | | 1.23.1 | 2015-05-26 | 1354 | | 1.24 | 2015-05-26 | 223 | | 1.25 | 2015-05-26 | 4319 | | 1.25.1 | 2015-06-02 | 197 | -------------------------------------
Notes about the resulting table:
If a column contains numeric data (integer and/or floating point numbers) in all rows (ignoring column names of course) then the content of that column is right-aligned, as can be seen in the example above. The idea here is to make it easier to compare the numbers in different columns to each other.
The column names are highlighted in color so they stand out a bit more (see also
HIGHLIGHT_COLOR). The following screen shot shows what that looks like (my terminals are always set to white text on a black background):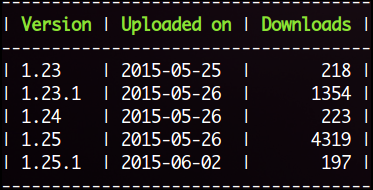
- data – An iterable (e.g. a
-
humanfriendly.tables.format_robust_table(data, column_names)¶ Render tabular data with one column per line (allowing columns with line breaks).
Parameters: Returns: The rendered table (a string).
Here’s an example:
>>> from humanfriendly.tables import format_robust_table >>> column_names = ['Version', 'Uploaded on', 'Downloads'] >>> humanfriendly_releases = [ ... ['1.23', '2015-05-25', '218'], ... ['1.23.1', '2015-05-26', '1354'], ... ['1.24', '2015-05-26', '223'], ... ['1.25', '2015-05-26', '4319'], ... ['1.25.1', '2015-06-02', '197'], ... ] >>> print(format_robust_table(humanfriendly_releases, column_names)) ----------------------- Version: 1.23 Uploaded on: 2015-05-25 Downloads: 218 ----------------------- Version: 1.23.1 Uploaded on: 2015-05-26 Downloads: 1354 ----------------------- Version: 1.24 Uploaded on: 2015-05-26 Downloads: 223 ----------------------- Version: 1.25 Uploaded on: 2015-05-26 Downloads: 4319 ----------------------- Version: 1.25.1 Uploaded on: 2015-06-02 Downloads: 197 -----------------------
The column names are highlighted in bold font and color so they stand out a bit more (see
HIGHLIGHT_COLOR).
-
humanfriendly.tables.format_rst_table(data, column_names=None)¶ Render a table in reStructuredText format.
Parameters: Returns: The rendered table (a string).
Here’s an example:
>>> from humanfriendly.tables import format_rst_table >>> column_names = ['Version', 'Uploaded on', 'Downloads'] >>> humanfriendly_releases = [ ... ['1.23', '2015-05-25', '218'], ... ['1.23.1', '2015-05-26', '1354'], ... ['1.24', '2015-05-26', '223'], ... ['1.25', '2015-05-26', '4319'], ... ['1.25.1', '2015-06-02', '197'], ... ] >>> print(format_rst_table(humanfriendly_releases, column_names)) ======= =========== ========= Version Uploaded on Downloads ======= =========== ========= 1.23 2015-05-25 218 1.23.1 2015-05-26 1354 1.24 2015-05-26 223 1.25 2015-05-26 4319 1.25.1 2015-06-02 197 ======= =========== =========
humanfriendly.terminal¶
Interaction with interactive text terminals.
The terminal module makes it easy to interact with
interactive text terminals and format text for rendering on such terminals. If
the terms used in the documentation of this module don’t make sense to you then
please refer to the Wikipedia article on ANSI escape sequences for details
about how ANSI escape sequences work.
This module was originally developed for use on UNIX systems, but since then
Windows 10 gained native support for ANSI escape sequences and this module was
enhanced to recognize and support this. For details please refer to the
enable_ansi_support() function.
Note
Deprecated names
The following aliases exist to preserve backwards compatibility, however a DeprecationWarning is triggered when they are accessed, because these aliases will be removed in a future release.
-
humanfriendly.terminal.HTMLConverter¶ Alias for
humanfriendly.terminal.html.HTMLConverter.
-
humanfriendly.terminal.format_usage¶ Alias for
humanfriendly.usage.format_usage.
-
humanfriendly.terminal.find_meta_variables¶ Alias for
humanfriendly.usage.find_meta_variables.
-
humanfriendly.terminal.html_to_ansi¶ Alias for
humanfriendly.terminal.html.html_to_ansi.
-
humanfriendly.terminal.ANSI_CSI= '\x1b['¶ The ANSI “Control Sequence Introducer” (a string).
-
humanfriendly.terminal.ANSI_SGR= 'm'¶ The ANSI “Select Graphic Rendition” sequence (a string).
-
humanfriendly.terminal.ANSI_ERASE_LINE= '\x1b[K'¶ The ANSI escape sequence to erase the current line (a string).
-
humanfriendly.terminal.ANSI_RESET= '\x1b[0m'¶ The ANSI escape sequence to reset styling (a string).
-
humanfriendly.terminal.ANSI_HIDE_CURSOR= '\x1b[?25l'¶ The ANSI escape sequence to hide the text cursor (a string).
-
humanfriendly.terminal.ANSI_SHOW_CURSOR= '\x1b[?25h'¶ The ANSI escape sequence to show the text cursor (a string).
-
humanfriendly.terminal.ANSI_COLOR_CODES= {'black': 0, 'blue': 4, 'cyan': 6, 'green': 2, 'magenta': 5, 'red': 1, 'white': 7, 'yellow': 3}¶ A dictionary with (name, number) pairs of portable color codes. Used by
ansi_style()to generate ANSI escape sequences that change font color.
-
humanfriendly.terminal.ANSI_TEXT_STYLES= {'bold': 1, 'faint': 2, 'inverse': 7, 'italic': 3, 'strike_through': 9, 'underline': 4}¶ A dictionary with (name, number) pairs of text styles (effects). Used by
ansi_style()to generate ANSI escape sequences that change text styles. Only widely supported text styles are included here.
-
humanfriendly.terminal.CLEAN_OUTPUT_PATTERN= <_sre.SRE_Pattern object>¶ A compiled regular expression used to separate significant characters from other text.
This pattern is used by
clean_terminal_output()to split terminal output into regular text versus backspace, carriage return and line feed characters and ANSI ‘erase line’ escape sequences.
-
humanfriendly.terminal.DEFAULT_LINES= 25¶ The default number of lines in a terminal (an integer).
-
humanfriendly.terminal.DEFAULT_COLUMNS= 80¶ The default number of columns in a terminal (an integer).
-
humanfriendly.terminal.DEFAULT_ENCODING= 'UTF-8'¶ The output encoding for Unicode strings.
-
humanfriendly.terminal.HIGHLIGHT_COLOR= 'green'¶ The color used to highlight important tokens in formatted text (e.g. the usage message of the
humanfriendlyprogram). If the environment variable$HUMANFRIENDLY_HIGHLIGHT_COLORis set it determines the value ofHIGHLIGHT_COLOR.
-
humanfriendly.terminal.ansi_strip(text, readline_hints=True)¶ Strip ANSI escape sequences from the given string.
Parameters: - text – The text from which ANSI escape sequences should be removed (a string).
- readline_hints – If
Truethenreadline_strip()is used to remove readline hints from the string.
Returns: The text without ANSI escape sequences (a string).
-
humanfriendly.terminal.ansi_style(**kw)¶ Generate ANSI escape sequences for the given color and/or style(s).
Parameters: - color –
The foreground color. Three types of values are supported:
- The name of a color (one of the strings ‘black’, ‘red’, ‘green’, ‘yellow’, ‘blue’, ‘magenta’, ‘cyan’ or ‘white’).
- An integer that refers to the 256 color mode palette.
- A tuple or list with three integers representing an RGB (red, green, blue) value.
The value
None(the default) means no escape sequence to switch color will be emitted. - background – The background color (see the description of the color argument).
- bright – Use high intensity colors instead of default colors
(a boolean, defaults to
False). - readline_hints – If
Truethenreadline_wrap()is applied to the generated ANSI escape sequences (the default isFalse). - kw – Any additional keyword arguments are expected to match a key
in the
ANSI_TEXT_STYLESdictionary. If the argument’s value evaluates toTruethe respective style will be enabled.
Returns: The ANSI escape sequences to enable the requested text styles or an empty string if no styles were requested.
Raises: ValueErrorwhen an invalid color name is given.Even though only eight named colors are supported, the use of bright=True and faint=True increases the number of available colors to around 24 (it may be slightly lower, for example because faint black is just black).
Support for 8-bit colors
In release 4.7 support for 256 color mode was added. While this significantly increases the available colors it’s not very human friendly in usage because you need to look up color codes in the 256 color mode palette.
You can use the
humanfriendly --democommand to get a demonstration of the available colors, see also the screen shot below. Note that the small font size in the screen shot was so that the demonstration of 256 color mode support would fit into a single screen shot without scrolling :-) (I wasn’t feeling very creative).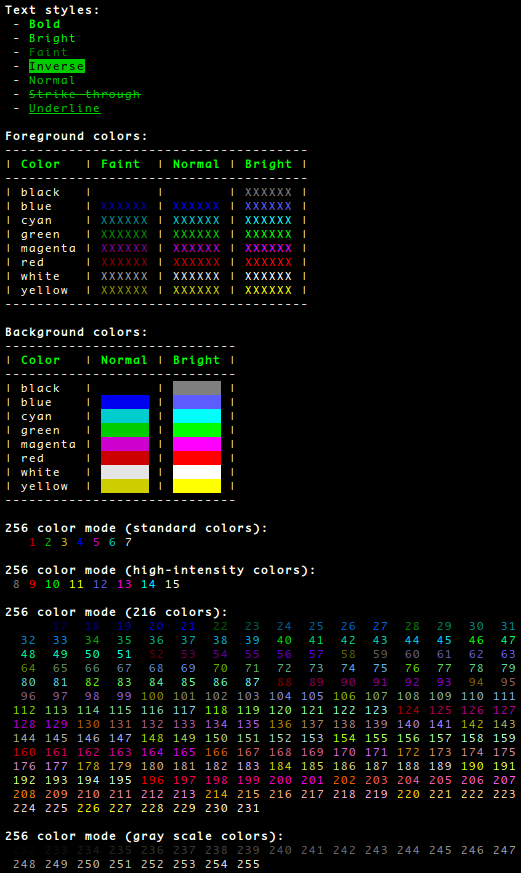
Support for 24-bit colors
In release 4.14 support for 24-bit colors was added by accepting a tuple or list with three integers representing the RGB (red, green, blue) value of a color. This is not included in the demo because rendering millions of colors was deemed unpractical ;-).
- color –
-
humanfriendly.terminal.ansi_width(text)¶ Calculate the effective width of the given text (ignoring ANSI escape sequences).
Parameters: text – The text whose width should be calculated (a string). Returns: The width of the text without ANSI escape sequences (an integer). This function uses
ansi_strip()to strip ANSI escape sequences from the given string and returns the length of the resulting string.
-
humanfriendly.terminal.ansi_wrap(text, **kw)¶ Wrap text in ANSI escape sequences for the given color and/or style(s).
Parameters: - text – The text to wrap (a string).
- kw – Any keyword arguments are passed to
ansi_style().
Returns: The result of this function depends on the keyword arguments:
- If
ansi_style()generates an ANSI escape sequence based on the keyword arguments, the given text is prefixed with the generated ANSI escape sequence and suffixed withANSI_RESET. - If
ansi_style()returns an empty string then the text given by the caller is returned unchanged.
-
humanfriendly.terminal.auto_encode(stream, text, *args, **kw)¶ Reliably write Unicode strings to the terminal.
Parameters: - stream – The file-like object to write to (a value like
sys.stdoutorsys.stderr). - text – The text to write to the stream (a string).
- args – Refer to
format(). - kw – Refer to
format().
Renders the text using
format()and writes it to the given stream. If anUnicodeEncodeErroris encountered in doing so, the text is encoded usingDEFAULT_ENCODINGand the write is retried. The reasoning behind this rather blunt approach is that it’s preferable to get output on the command line in the wrong encoding then to have the Python program blow up with aUnicodeEncodeErrorexception.- stream – The file-like object to write to (a value like
-
humanfriendly.terminal.clean_terminal_output(text)¶ Clean up the terminal output of a command.
Parameters: text – The raw text with special characters (a Unicode string). Returns: A list of Unicode strings (one for each line). This function emulates the effect of backspace (0x08), carriage return (0x0D) and line feed (0x0A) characters and the ANSI ‘erase line’ escape sequence on interactive terminals. It’s intended to clean up command output that was originally meant to be rendered on an interactive terminal and that has been captured using e.g. the script program [3] or the
ptymodule [4].[3] My coloredlogs package supports the coloredlogs --to-htmlcommand which uses script to fool a subprocess into thinking that it’s connected to an interactive terminal (in order to get it to emit ANSI escape sequences).[4] My capturer package uses the ptymodule to fool the current process and subprocesses into thinking they are connected to an interactive terminal (in order to get them to emit ANSI escape sequences).Some caveats about the use of this function:
- Strictly speaking the effect of carriage returns cannot be emulated outside of an actual terminal due to the interaction between overlapping output, terminal widths and line wrapping. The goal of this function is to sanitize noise in terminal output while preserving useful output. Think of it as a useful and pragmatic but possibly lossy conversion.
- The algorithm isn’t smart enough to properly handle a pair of ANSI escape sequences that open before a carriage return and close after the last carriage return in a linefeed delimited string; the resulting string will contain only the closing end of the ANSI escape sequence pair. Tracking this kind of complexity requires a state machine and proper parsing.
-
humanfriendly.terminal.connected_to_terminal(stream=None)¶ Check if a stream is connected to a terminal.
Parameters: stream – The stream to check (a file-like object, defaults to sys.stdout).Returns: Trueif the stream is connected to a terminal,Falseotherwise.See also
terminal_supports_colors().
-
humanfriendly.terminal.enable_ansi_support()¶ Try to enable support for ANSI escape sequences (required on Windows).
Returns: Trueif ANSI is supported,Falseotherwise.This functions checks for the following supported configurations, in the given order:
On Windows, if
have_windows_native_ansi_support()confirms native support for ANSI escape sequencesctypeswill be used to enable this support.On Windows, if the environment variable
$ANSICONis set nothing is done because it is assumed that support for ANSI escape sequences has already been enabled via ansicon.On Windows, an attempt is made to import and initialize the Python package colorama instead (of course for this to work colorama has to be installed).
On other platforms this function calls
connected_to_terminal()to determine whether ANSI escape sequences are supported (that is to say all platforms that are not Windows are assumed to support ANSI escape sequences natively, without weird contortions like above).This makes it possible to call
enable_ansi_support()unconditionally without checking the current platform.
The
cached()decorator is used to ensure that this function is only executed once, but its return value remains available on later calls.
-
humanfriendly.terminal.find_terminal_size()¶ Determine the number of lines and columns visible in the terminal.
Returns: A tuple of two integers with the line and column count. The result of this function is based on the first of the following three methods that works:
- First
find_terminal_size_using_ioctl()is tried, - then
find_terminal_size_using_stty()is tried, - finally
DEFAULT_LINESandDEFAULT_COLUMNSare returned.
Note
The
find_terminal_size()function performs the steps above every time it is called, the result is not cached. This is because the size of a virtual terminal can change at any time and the result offind_terminal_size()should be correct.Pre-emptive snarky comment: It’s possible to cache the result of this function and use
signal.SIGWINCHto refresh the cached values!Response: As a library I don’t consider it the role of the
humanfriendly.terminalmodule to install a process wide signal handler …- First
-
humanfriendly.terminal.find_terminal_size_using_ioctl(stream)¶ Find the terminal size using
fcntl.ioctl().Parameters: stream – A stream connected to the terminal (a file object with a filenoattribute).Returns: A tuple of two integers with the line and column count. Raises: This function can raise exceptions but I’m not going to document them here, you should be using find_terminal_size().Based on an implementation found on StackOverflow.
-
humanfriendly.terminal.find_terminal_size_using_stty()¶ Find the terminal size using the external command
stty size.Parameters: stream – A stream connected to the terminal (a file object). Returns: A tuple of two integers with the line and column count. Raises: This function can raise exceptions but I’m not going to document them here, you should be using find_terminal_size().
-
humanfriendly.terminal.get_pager_command(text=None)¶ Get the command to show a text on the terminal using a pager.
Parameters: text – The text to print to the terminal (a string). Returns: A list of strings with the pager command and arguments. The use of a pager helps to avoid the wall of text effect where the user has to scroll up to see where the output began (not very user friendly).
If the given text contains ANSI escape sequences the command
less --RAW-CONTROL-CHARSis used, otherwise the environment variable$PAGERis used (if$PAGERisn’t set less is used).When the selected pager is less, the following options are used to make the experience more user friendly:
--quit-if-one-screencauses less to automatically exit if the entire text can be displayed on the first screen. This makes the use of a pager transparent for smaller texts (because the operator doesn’t have to quit the pager).--no-initprevents less from clearing the screen when it exits. This ensures that the operator gets a chance to review the text (for example a usage message) after quitting the pager, while composing the next command.
-
humanfriendly.terminal.have_windows_native_ansi_support()¶ Check if we’re running on a Windows 10 release with native support for ANSI escape sequences.
Returns: Trueif so,Falseotherwise.The
cached()decorator is used as a minor performance optimization. Semantically this should have zero impact because the answer doesn’t change in the lifetime of a computer process.
-
humanfriendly.terminal.message(text, *args, **kw)¶ Print a formatted message to the standard error stream.
For details about argument handling please refer to
format().Renders the message using
format()and writes the resulting string (followed by a newline) tosys.stderrusingauto_encode().
-
humanfriendly.terminal.output(text, *args, **kw)¶ Print a formatted message to the standard output stream.
For details about argument handling please refer to
format().Renders the message using
format()and writes the resulting string (followed by a newline) tosys.stdoutusingauto_encode().
-
humanfriendly.terminal.readline_strip(expr)¶ Remove readline hints from a string.
Parameters: text – The text to strip (a string). Returns: The stripped text.
-
humanfriendly.terminal.readline_wrap(expr)¶ Wrap an ANSI escape sequence in readline hints.
Parameters: text – The text with the escape sequence to wrap (a string). Returns: The wrapped text.
-
humanfriendly.terminal.show_pager(formatted_text, encoding='UTF-8')¶ Print a large text to the terminal using a pager.
Parameters: - formatted_text – The text to print to the terminal (a string).
- encoding – The name of the text encoding used to encode the formatted
text if the formatted text is a Unicode string (a string,
defaults to
DEFAULT_ENCODING).
When
connected_to_terminal()returnsTruea pager is used to show the text on the terminal, otherwise the text is printed directly without invoking a pager.The use of a pager helps to avoid the wall of text effect where the user has to scroll up to see where the output began (not very user friendly).
Refer to
get_pager_command()for details about the command line that’s used to invoke the pager.
-
humanfriendly.terminal.terminal_supports_colors(stream=None)¶ Check if a stream is connected to a terminal that supports ANSI escape sequences.
Parameters: stream – The stream to check (a file-like object, defaults to sys.stdout).Returns: Trueif the terminal supports ANSI escape sequences,Falseotherwise.This function was originally inspired by the implementation of django.core.management.color.supports_color() but has since evolved significantly.
-
humanfriendly.terminal.usage(usage_text)¶ Print a human friendly usage message to the terminal.
Parameters: text – The usage message to print (a string). This function does two things:
- If
sys.stdoutis connected to a terminal (seeconnected_to_terminal()) then the usage message is formatted usingformat_usage(). - The usage message is shown using a pager (see
show_pager()).
- If
-
humanfriendly.terminal.warning(text, *args, **kw)¶ Show a warning message on the terminal.
For details about argument handling please refer to
format().Renders the message using
format()and writes the resulting string (followed by a newline) tosys.stderrusingauto_encode().If
sys.stderris connected to a terminal that supports colors,ansi_wrap()is used to color the message in a red font (to make the warning stand out from surrounding text).
humanfriendly.terminal.html¶
Convert HTML with simple text formatting to text with ANSI escape sequences.
-
humanfriendly.terminal.html.html_to_ansi(data, callback=None)¶ Convert HTML with simple text formatting to text with ANSI escape sequences.
Parameters: - data – The HTML to convert (a string).
- callback – Optional callback to pass to
HTMLConverter.
Returns: Text with ANSI escape sequences (a string).
Please refer to the documentation of the
HTMLConverterclass for details about the conversion process (like which tags are supported) and an example with a screenshot.
-
class
humanfriendly.terminal.html.HTMLConverter(*args, **kw)¶ Convert HTML with simple text formatting to text with ANSI escape sequences.
The following text styles are supported:
- Bold:
<b>,<strong>and<span style="font-weight: bold;"> - Italic:
<i>,<em>and<span style="font-style: italic;"> - Strike-through:
<del>,<s>and<span style="text-decoration: line-through;"> - Underline:
<ins>,<u>and<span style="text-decoration: underline">
Colors can be specified as follows:
- Foreground color:
<span style="color: #RRGGBB;"> - Background color:
<span style="background-color: #RRGGBB;">
Here’s a small demonstration:
from humanfriendly.text import dedent from humanfriendly.terminal import html_to_ansi print(html_to_ansi(dedent(''' <b>Hello world!</b> <i>Is this thing on?</i> I guess I can <u>underline</u> or <s>strike-through</s> text? And what about <span style="color: red">color</span>? '''))) rainbow_colors = [ '#FF0000', '#E2571E', '#FF7F00', '#FFFF00', '#00FF00', '#96BF33', '#0000FF', '#4B0082', '#8B00FF', '#FFFFFF', ] html_rainbow = "".join('<span style="color: %s">o</span>' % c for c in rainbow_colors) print(html_to_ansi("Let's try a rainbow: %s" % html_rainbow))
Here’s what the results look like:
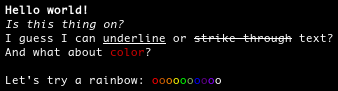
Some more details:
- Nested tags are supported, within reasonable limits.
- Text in
<code>and<pre>tags will be highlighted in a different color from the main text (currently this is yellow). <a href="URL">TEXT</a>is converted to the format “TEXT (URL)” where the uppercase symbols are highlighted in light blue with an underline.<div>,<p>and<pre>tags are considered block level tags and are wrapped in vertical whitespace to prevent their content from “running into” surrounding text. This may cause runs of multiple empty lines to be emitted. As a workaround the__call__()method will automatically callcompact_empty_lines()on the generated output before returning it to the caller. Of course this won’t work when output is set to something likesys.stdout.<br>is converted to a single plain text line break.
Implementation notes:
- A list of dictionaries with style information is used as a stack where new styling can be pushed and a pop will restore the previous styling. When new styling is pushed, it is merged with (but overrides) the current styling.
- If you’re going to be converting a lot of HTML it might be useful from
a performance standpoint to re-use an existing
HTMLConverterobject for unrelated HTML fragments, in this case take a look at the__call__()method (it makes this use case very easy).
New in version 4.15:
humanfriendly.terminal.HTMLConverterwas added to the humanfriendly package during the initial development of my new chat-archive project, whose command line interface makes for a great demonstration of the flexibility that this feature provides (hint: check out how the search keyword highlighting combines with the regular highlighting).-
BLOCK_TAGS= ('div', 'p', 'pre')¶ The names of tags that are padded with vertical whitespace.
-
__init__(*args, **kw)¶ Initialize an
HTMLConverterobject.Parameters: - callback – Optional keyword argument to specify a function that will be called to process text fragments before they are emitted on the output stream. Note that link text and preformatted text fragments are not processed by this callback.
- output – Optional keyword argument to redirect the output to the
given file-like object. If this is not given a new
StringIOobject is created.
-
__call__(data)¶ Reset the parser, convert some HTML and get the text with ANSI escape sequences.
Parameters: data – The HTML to convert to text (a string). Returns: The converted text (only in case output is a StringIOobject).
-
current_style¶ Get the current style from the top of the stack (a dictionary).
-
close()¶ Close previously opened ANSI escape sequences.
This method overrides the same method in the superclass to ensure that an
ANSI_RESETcode is emitted when parsing reaches the end of the input but a style is still active. This is intended to prevent malformed HTML from messing up terminal output.
-
emit_style(style=None)¶ Emit an ANSI escape sequence for the given or current style to the output stream.
Parameters: style – A dictionary with arguments for ansi_style()orNone, in which case the style at the top of the stack is emitted.
-
handle_charref(value)¶ Process a decimal or hexadecimal numeric character reference.
Parameters: value – The decimal or hexadecimal value (a string).
-
handle_data(data)¶ Process textual data.
Parameters: data – The decoded text (a string).
-
handle_endtag(tag)¶ Process the end of an HTML tag.
Parameters: tag – The name of the tag (a string).
-
handle_entityref(name)¶ Process a named character reference.
Parameters: name – The name of the character reference (a string).
-
handle_starttag(tag, attrs)¶ Process the start of an HTML tag.
Parameters: - tag – The name of the tag (a string).
- attrs – A list of tuples with two strings each.
-
normalize_url(url)¶ Normalize a URL to enable string equality comparison.
Parameters: url – The URL to normalize (a string). Returns: The normalized URL (a string).
-
parse_color(value)¶ Convert a CSS color to something that
ansi_style()understands.Parameters: value – A string like rgb(1,2,3),#AABBCCoryellow.Returns: A color value supported by ansi_style()orNone.
-
push_styles(**changes)¶ Push new style information onto the stack.
Parameters: changes – Any keyword arguments are passed on to ansi_style().This method is a helper for
handle_starttag()that does the following:- Make a copy of the current styles (from the top of the stack),
- Apply the given changes to the copy of the current styles,
- Add the new styles to the stack,
- Emit the appropriate ANSI escape sequence to the output stream.
-
render_url(url)¶ Prepare a URL for rendering on the terminal.
Parameters: url – The URL to simplify (a string). Returns: The simplified URL (a string). This method pre-processes a URL before rendering on the terminal. The following modifications are made:
- The
mailto:prefix is stripped. - Spaces are converted to
%20. - A trailing parenthesis is converted to
%29.
- The
-
reset()¶ Reset the state of the HTML parser and ANSI converter.
When output is a
StringIOobject a new instance will be created (and the old one garbage collected).
-
urls_match(a, b)¶ Compare two URLs for equality using
normalize_url().Parameters: - a – A string containing a URL.
- b – A string containing a URL.
Returns: This method is used by
handle_endtag()to omit the URL of a hyperlink (<a href="...">) when the link text is that same URL.
- Bold:
humanfriendly.terminal.spinners¶
Support for spinners that represent progress on interactive terminals.
The Spinner class shows a “spinner” on the terminal to let the user
know that something is happening during long running operations that would
otherwise be silent (leaving the user to wonder what they’re waiting for).
Below are some visual examples that should illustrate the point.
Simple spinners:
Here’s a screen capture that shows the simplest form of spinner:
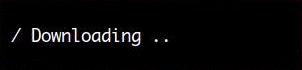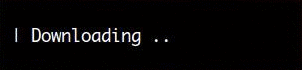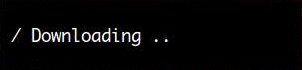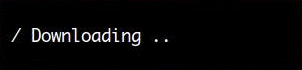
The following code was used to create the spinner above:
import itertools import time from humanfriendly import Spinner with Spinner(label="Downloading") as spinner: for i in itertools.count(): # Do something useful here. time.sleep(0.1) # Advance the spinner. spinner.step()
Spinners that show elapsed time:
Here’s a spinner that shows the elapsed time since it started:
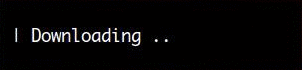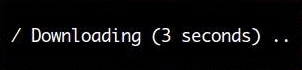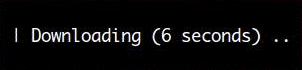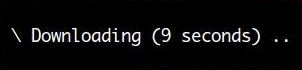
The following code was used to create the spinner above:
import itertools import time from humanfriendly import Spinner, Timer with Spinner(label="Downloading", timer=Timer()) as spinner: for i in itertools.count(): # Do something useful here. time.sleep(0.1) # Advance the spinner. spinner.step()
Spinners that show progress:
Here’s a spinner that shows a progress percentage:

The following code was used to create the spinner above:
import itertools import random import time from humanfriendly import Spinner, Timer with Spinner(label="Downloading", total=100) as spinner: progress = 0 while progress < 100: # Do something useful here. time.sleep(0.1) # Advance the spinner. spinner.step(progress) # Determine the new progress value. progress += random.random() * 5
If you want to provide user feedback during a long running operation but it’s
not practical to periodically call the step() method consider
using AutomaticSpinner instead.
As you may already have noticed in the examples above, Spinner objects
can be used as context managers to automatically call Spinner.clear()
when the spinner ends.
-
humanfriendly.terminal.spinners.GLYPHS= ['-', '\\', '|', '/']¶ A list of strings with characters that together form a crude animation :-).
-
humanfriendly.terminal.spinners.MINIMUM_INTERVAL= 0.2¶ Spinners are redrawn with a frequency no higher than this number (a floating point number of seconds).
-
class
humanfriendly.terminal.spinners.Spinner(**kw)¶ Show a spinner on the terminal as a simple means of feedback to the user.
-
__init__(**kw)¶ Initialize a
Spinnerobject.Parameters: - label – The label for the spinner (a string or
None, defaults toNone). - total – The expected number of steps (an integer or
None). If this is provided the spinner will show a progress percentage. - stream – The output stream to show the spinner on (a file-like object,
defaults to
sys.stderr). - interactive –
Trueto enable rendering of the spinner,Falseto disable (defaults to the result ofstream.isatty()). - timer – A
Timerobject (optional). If this is given the spinner will show the elapsed time according to the timer. - interval – The spinner will be updated at most once every this many seconds
(a floating point number, defaults to
MINIMUM_INTERVAL). - glyphs – A list of strings with single characters that are drawn in the same
place in succession to implement a simple animated effect (defaults
to
GLYPHS).
- label – The label for the spinner (a string or
-
step(progress=0, label=None)¶ Advance the spinner by one step and redraw it.
Parameters: - progress – The number of the current step, relative to the total
given to the
Spinnerconstructor (an integer, optional). If not provided the spinner will not show progress. - label – The label to use while redrawing (a string, optional). If
not provided the label given to the
Spinnerconstructor is used instead.
This method advances the spinner by one step without starting a new line, causing an animated effect which is very simple but much nicer than waiting for a prompt which is completely silent for a long time.
- progress – The number of the current step, relative to the total
given to the
-
sleep()¶ Sleep for a short period before redrawing the spinner.
This method is useful when you know you’re dealing with code that will call
step()at a high frequency. It will sleep for the interval with which the spinner is redrawn (less than a second). This avoids creating the equivalent of a busy loop that’s rate limiting the spinner 99% of the time.This method doesn’t redraw the spinner, you still have to call
step()in order to do that.
-
clear()¶ Clear the spinner.
The next line which is shown on the standard output or error stream after calling this method will overwrite the line that used to show the spinner.
-
__exit__(exc_type=None, exc_value=None, traceback=None)¶ Clear the spinner when leaving the context.
-
-
class
humanfriendly.terminal.spinners.AutomaticSpinner(label, show_time=True)¶ Show a spinner on the terminal that automatically starts animating.
This class shows a spinner on the terminal (just like
Spinnerdoes) that automatically starts animating. This class should be used as a context manager using thewithstatement. The animation continues for as long as the context is active.AutomaticSpinnerprovides an alternative toSpinnerfor situations where it is not practical for the caller to periodically callstep()to advance the animation, e.g. because you’re performing a blocking call and don’t fancy implementing threading or subprocess handling just to provide some user feedback.This works using the
multiprocessingmodule by spawning a subprocess to render the spinner while the main process is busy doing something more useful. By using thewithstatement you’re guaranteed that the subprocess is properly terminated at the appropriate time.-
__init__(label, show_time=True)¶ Initialize an automatic spinner.
Parameters: - label – The label for the spinner (a string).
- show_time – If this is
True(the default) then the spinner shows elapsed time.
-
__enter__()¶ Enable the use of automatic spinners as context managers.
-
__exit__(exc_type=None, exc_value=None, traceback=None)¶ Enable the use of automatic spinners as context managers.
-
humanfriendly.testing¶
Utility classes and functions that make it easy to write unittest compatible test suites.
Over the years I’ve developed the habit of writing test suites for Python
projects using the unittest module. During those years I’ve come to know
pytest and in fact I use pytest to run my test suites (due to
its much better error reporting) but I’ve yet to publish a test suite that
requires pytest. I have several reasons for doing so:
- It’s nice to keep my test suites as simple and accessible as possible and not requiring a specific test runner is part of that attitude.
- Whereas
unittestis quite explicit, pytest contains a lot of magic, which kind of contradicts the Python mantra “explicit is better than implicit” (IMHO).
-
humanfriendly.testing.configure_logging(log_level=logging.DEBUG)¶ Automatically configure logging to the terminal.
Parameters: log_level – The log verbosity (a number, defaults to logging.DEBUG).When
coloredlogsis installedcoloredlogs.install()will be used to configure logging to the terminal. When this fails with anImportErrorthenlogging.basicConfig()is used as a fall back.
-
humanfriendly.testing.make_dirs(pathname)¶ Create missing directories.
Parameters: pathname – The pathname of a directory (a string).
-
humanfriendly.testing.retry(func, timeout=60, exc_type=AssertionError)¶ Retry a function until assertions no longer fail.
Parameters: - func – A callable. When the callable returns
Falseit will also be retried. - timeout – The number of seconds after which to abort (a number, defaults to 60).
- exc_type – The type of exceptions to retry (defaults
to
AssertionError).
Returns: The value returned by func.
Raises: Once the timeout has expired
retry()will raise the previously retried assertion error. When func keeps returningFalseuntil timeout expiresCallableTimedOutwill be raised.This function sleeps between retries to avoid claiming CPU cycles we don’t need. It starts by sleeping for 0.1 second but adjusts this to one second as the number of retries grows.
- func – A callable. When the callable returns
-
humanfriendly.testing.run_cli(entry_point, *arguments, **options)¶ Test a command line entry point.
Parameters: - entry_point – The function that implements the command line interface (a callable).
- arguments – Any positional arguments (strings) become the command
line arguments (
sys.argvitems 1-N). - options –
The following keyword arguments are supported:
- capture
- Whether to use
CaptureOutput. Defaults toTruebut can be disabled by passingFalseinstead. - input
- Refer to
CaptureOutput. - merged
- Refer to
CaptureOutput. - program_name
- Used to set
sys.argvitem 0.
Returns: A tuple with two values:
- The return code (an integer).
- The captured output (a string).
-
humanfriendly.testing.skip_on_raise(*exc_types)¶ Decorate a test function to translation specific exception types to
unittest.SkipTest.Parameters: exc_types – One or more positional arguments give the exception types to be translated to unittest.SkipTest.Returns: A decorator function specialized to exc_types.
-
humanfriendly.testing.touch(filename)¶ The equivalent of the UNIX touch program in Python.
Parameters: filename – The pathname of the file to touch (a string). Note that missing directories are automatically created using
make_dirs().
-
class
humanfriendly.testing.ContextManager¶ Base class to enable composition of context managers.
-
__enter__()¶ Enable use as context managers.
-
__exit__(exc_type=None, exc_value=None, traceback=None)¶ Enable use as context managers.
-
-
class
humanfriendly.testing.PatchedAttribute(obj, name, value)¶ Context manager that temporary replaces an object attribute using
setattr().-
__init__(obj, name, value)¶ Initialize a
PatchedAttributeobject.Parameters: - obj – The object to patch.
- name – An attribute name.
- value – The value to set.
-
__enter__()¶ Replace (patch) the attribute.
Returns: The object whose attribute was patched.
-
__exit__(exc_type=None, exc_value=None, traceback=None)¶ Restore the attribute to its original value.
-
-
class
humanfriendly.testing.PatchedItem(obj, item, value)¶ Context manager that temporary replaces an object item using
__setitem__().-
__init__(obj, item, value)¶ Initialize a
PatchedItemobject.Parameters: - obj – The object to patch.
- item – The item to patch.
- value – The value to set.
-
__enter__()¶ Replace (patch) the item.
Returns: The object whose item was patched.
-
__exit__(exc_type=None, exc_value=None, traceback=None)¶ Restore the item to its original value.
-
-
class
humanfriendly.testing.TemporaryDirectory(**options)¶ Easy temporary directory creation & cleanup using the
withstatement.Here’s an example of how to use this:
with TemporaryDirectory() as directory: # Do something useful here. assert os.path.isdir(directory)
-
__init__(**options)¶ Initialize a
TemporaryDirectoryobject.Parameters: options – Any keyword arguments are passed on to tempfile.mkdtemp().
-
__enter__()¶ Create the temporary directory using
tempfile.mkdtemp().Returns: The pathname of the directory (a string).
-
__exit__(exc_type=None, exc_value=None, traceback=None)¶ Cleanup the temporary directory using
shutil.rmtree().
-
-
class
humanfriendly.testing.CustomSearchPath(isolated=False)¶ Context manager to temporarily customize
$PATH(the executable search path).This class is a composition of the
PatchedItemandTemporaryDirectorycontext managers.-
__init__(isolated=False)¶ Initialize a
CustomSearchPathobject.Parameters: isolated – Trueto clear the original search path,Falseto add the temporary directory to the start of the search path.
-
__enter__()¶ Activate the custom
$PATH.Returns: The pathname of the directory that has been added to $PATH(a string).
-
__exit__(exc_type=None, exc_value=None, traceback=None)¶ Deactivate the custom
$PATH.
-
current_search_path¶ The value of
$PATHoros.defpath(a string).
-
-
class
humanfriendly.testing.MockedProgram(name, returncode=0, script=None)¶ Context manager to mock the existence of a program (executable).
This class extends the functionality of
CustomSearchPath.-
__init__(name, returncode=0, script=None)¶ Initialize a
MockedProgramobject.Parameters: - name – The name of the program (a string).
- returncode – The return code that the program should emit (a number, defaults to zero).
- script – Shell script code to include in the mocked program (a
string or
None). This can be used to mock a program that is expected to generate specific output.
-
__enter__()¶ Create the mock program.
Returns: The pathname of the directory that has been added to $PATH(a string).
-
__exit__(*args, **kw)¶ Ensure that the mock program was run.
Raises: AssertionErrorwhen the mock program hasn’t been run.
-
-
class
humanfriendly.testing.CaptureOutput(merged=False, input='', enabled=True)¶ Context manager that captures what’s written to
sys.stdoutandsys.stderr.-
stdout¶ The
CaptureBufferobject used to capture the standard output stream.
-
stderr¶ The
CaptureBufferobject used to capture the standard error stream.
-
__init__(merged=False, input='', enabled=True)¶ Initialize a
CaptureOutputobject.Parameters: - merged –
Trueto merge the streams,Falseto capture them separately. - input – The data that reads from
sys.stdinshould return (a string). - enabled –
Trueto enable capturing (the default),Falseotherwise. This makes it easy to unconditionally useCaptureOutputin awithblock while preserving the choice to opt out of capturing output.
- merged –
-
__enter__()¶ Start capturing what’s written to
sys.stdoutandsys.stderr.
-
__exit__(exc_type=None, exc_value=None, traceback=None)¶ Stop capturing what’s written to
sys.stdoutandsys.stderr.
-
getvalue()¶ Get the text written to
sys.stdout.
-
-
class
humanfriendly.testing.CaptureBuffer(buf='')¶ Helper for
CaptureOutputto provide an easy to use API.The two methods defined by this subclass were specifically chosen to match the names of the methods provided by my capturer package which serves a similar role as
CaptureOutputbut knows how to simulate an interactive terminal (tty).-
get_lines()¶ Get the contents of the buffer split into separate lines.
-
get_text()¶ Get the contents of the buffer as a Unicode string.
-
-
class
humanfriendly.testing.TestCase(*args, **kw)¶ Subclass of
unittest.TestCasewith automatic logging and other miscellaneous features.-
__init__(*args, **kw)¶ Initialize a
TestCaseobject.Any positional and/or keyword arguments are passed on to the initializer of the superclass.
-
setUp(log_level=logging.DEBUG)¶ Automatically configure logging to the terminal.
Parameters: log_level – Refer to configure_logging().The
setUp()method is automatically called byunittest.TestCasebefore each test method starts. It does two things:- Logging to the terminal is configured using
configure_logging(). - Before the test method starts a newline is emitted, to separate the
name of the test method (which will be printed to the terminal by
unittestor pytest) from the first line of logging output that the test method is likely going to generate.
- Logging to the terminal is configured using
-
humanfriendly.text¶
Simple text manipulation functions.
The text module contains simple functions to manipulate text:
- The
concatenate()andpluralize()functions make it easy to generate human friendly output. - The
format(),compact()anddedent()functions provide a clean and simple to use syntax for composing large text fragments with interpolated variables. - The
tokenize()function parses simple user input.
-
humanfriendly.text.compact(text, *args, **kw)¶ Compact whitespace in a string.
Trims leading and trailing whitespace, replaces runs of whitespace characters with a single space and interpolates any arguments using
format().Parameters: Returns: The compacted text (a string).
Here’s an example of how I like to use the
compact()function, this is an example from a random unrelated project I’m working on at the moment:raise PortDiscoveryError(compact(""" Failed to discover port(s) that Apache is listening on! Maybe I'm parsing the wrong configuration file? ({filename}) """, filename=self.ports_config))
The combination of
compact()and Python’s multi line strings allows me to write long text fragments with interpolated variables that are easy to write, easy to read and work well with Python’s whitespace sensitivity.
-
humanfriendly.text.compact_empty_lines(text)¶ Replace repeating empty lines with a single empty line (similar to
cat -s).Parameters: text – The text in which to compact empty lines (a string). Returns: The text with empty lines compacted (a string).
-
humanfriendly.text.concatenate(items, conjunction='and', serial_comma=False)¶ Concatenate a list of items in a human friendly way.
Parameters: - items – A sequence of strings.
- conjunction – The word to use before the last item (a string, defaults to “and”).
- serial_comma –
Trueto use a serial comma,Falseotherwise (defaults toFalse).
Returns: A single string.
>>> from humanfriendly.text import concatenate >>> concatenate(["eggs", "milk", "bread"]) 'eggs, milk and bread'
-
humanfriendly.text.dedent(text, *args, **kw)¶ Dedent a string (remove common leading whitespace from all lines).
Removes common leading whitespace from all lines in the string using
textwrap.dedent(), removes leading and trailing empty lines usingtrim_empty_lines()and interpolates any arguments usingformat().Parameters: Returns: The dedented text (a string).
The
compact()function’s documentation contains an example of how I like to use thecompact()anddedent()functions. The main difference is that I usecompact()for text that will be presented to the user (where whitespace is not so significant) anddedent()for data file and code generation tasks (where newlines and indentation are very significant).
-
humanfriendly.text.format(text, *args, **kw)¶ Format a string using the string formatting operator and/or
str.format().Parameters: - text – The text to format (a string).
- args – Any positional arguments are interpolated into the text using
the string formatting operator (
%). If no positional arguments are given no interpolation is done. - kw – Any keyword arguments are interpolated into the text using the
str.format()function. If no keyword arguments are given no interpolation is done.
Returns: The text with any positional and/or keyword arguments interpolated (a string).
The implementation of this function is so trivial that it seems silly to even bother writing and documenting it. Justifying this requires some context :-).
Why format() instead of the string formatting operator?
For really simple string interpolation Python’s string formatting operator is ideal, but it does have some strange quirks:
When you switch from interpolating a single value to interpolating multiple values you have to wrap them in tuple syntax. Because
format()takes a variable number of arguments it always receives a tuple (which saves me a context switch :-). Here’s an example:>>> from humanfriendly.text import format >>> # The string formatting operator. >>> print('the magic number is %s' % 42) the magic number is 42 >>> print('the magic numbers are %s and %s' % (12, 42)) the magic numbers are 12 and 42 >>> # The format() function. >>> print(format('the magic number is %s', 42)) the magic number is 42 >>> print(format('the magic numbers are %s and %s', 12, 42)) the magic numbers are 12 and 42
When you interpolate a single value and someone accidentally passes in a tuple your code raises a
TypeError. Becauseformat()takes a variable number of arguments it always receives a tuple so this can never happen. Here’s an example:>>> # How expecting to interpolate a single value can fail. >>> value = (12, 42) >>> print('the magic value is %s' % value) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: not all arguments converted during string formatting >>> # The following line works as intended, no surprises here! >>> print(format('the magic value is %s', value)) the magic value is (12, 42)
Why format() instead of the str.format() method?
When you’re doing complex string interpolation the
str.format()function results in more readable code, however I frequently find myself adding parentheses to force evaluation order. Theformat()function avoids this because of the relative priority between the comma and dot operators. Here’s an example:>>> "{adjective} example" + " " + "(can't think of anything less {adjective})".format(adjective='silly') "{adjective} example (can't think of anything less silly)" >>> ("{adjective} example" + " " + "(can't think of anything less {adjective})").format(adjective='silly') "silly example (can't think of anything less silly)" >>> format("{adjective} example" + " " + "(can't think of anything less {adjective})", adjective='silly') "silly example (can't think of anything less silly)"
The
compact()anddedent()functions are wrappers that combineformat()with whitespace manipulation to make it easy to write nice to read Python code.
-
humanfriendly.text.generate_slug(text, delimiter='-')¶ Convert text to a normalized “slug” without whitespace.
Parameters: - text – The original text, for example
Some Random Text!. - delimiter – The delimiter used to separate words
(defaults to the
-character).
Returns: The slug text, for example
some-random-text.Raises: ValueErrorwhen the provided text is nonempty but results in an empty slug.- text – The original text, for example
-
humanfriendly.text.is_empty_line(text)¶ Check if a text is empty or contains only whitespace.
Parameters: text – The text to check for “emptiness” (a string). Returns: Trueif the text is empty or contains only whitespace,Falseotherwise.
-
humanfriendly.text.join_lines(text)¶ Remove “hard wrapping” from the paragraphs in a string.
Parameters: text – The text to reformat (a string). Returns: The text without hard wrapping (a string). This function works by removing line breaks when the last character before a line break and the first character after the line break are both non-whitespace characters. This means that common leading indentation will break
join_lines()(in that case you can usededent()before callingjoin_lines()).
-
humanfriendly.text.pluralize(count, singular, plural=None)¶ Combine a count with the singular or plural form of a word.
Parameters: - count – The count (a number).
- singular – The singular form of the word (a string).
- plural – The plural form of the word (a string or
None).
Returns: The count and singular or plural word concatenated (a string).
See
pluralize_raw()for the logic underneathpluralize().
-
humanfriendly.text.pluralize_raw(count, singular, plural=None)¶ Select the singular or plural form of a word based on a count.
Parameters: - count – The count (a number).
- singular – The singular form of the word (a string).
- plural – The plural form of the word (a string or
None).
Returns: The singular or plural form of the word (a string).
When the given count is exactly 1.0 the singular form of the word is selected, in all other cases the plural form of the word is selected.
If the plural form of the word is not provided it is obtained by concatenating the singular form of the word with the letter “s”. Of course this will not always be correct, which is why you have the option to specify both forms.
-
humanfriendly.text.random_string(length=(25, 100), characters=string.ascii_letters)¶ Generate a random string.
Parameters: - length – The length of the string to be generated (a number or a tuple with two numbers). If this is a tuple then a random number between the two numbers given in the tuple is used.
- characters – The characters to be used (a string, defaults
to
string.ascii_letters).
Returns: A random string.
The
random_string()function is very useful in test suites; by the time I included it inhumanfriendly.textI had already included variants of this function in seven different test suites :-).
-
humanfriendly.text.split(text, delimiter=', ')¶ Split a comma-separated list of strings.
Parameters: - text – The text to split (a string).
- delimiter – The delimiter to split on (a string).
Returns: A list of zero or more nonempty strings.
Here’s the default behavior of Python’s built in
str.split()function:>>> 'foo,bar, baz,'.split(',') ['foo', 'bar', ' baz', '']
In contrast here’s the default behavior of the
split()function:>>> from humanfriendly.text import split >>> split('foo,bar, baz,') ['foo', 'bar', 'baz']
Here is an example that parses a nested data structure (a mapping of logging level names to one or more styles per level) that’s encoded in a string so it can be set as an environment variable:
>>> from pprint import pprint >>> encoded_data = 'debug=green;warning=yellow;error=red;critical=red,bold' >>> parsed_data = dict((k, split(v, ',')) for k, v in (split(kv, '=') for kv in split(encoded_data, ';'))) >>> pprint(parsed_data) {'debug': ['green'], 'warning': ['yellow'], 'error': ['red'], 'critical': ['red', 'bold']}
-
humanfriendly.text.split_paragraphs(text)¶ Split a string into paragraphs (one or more lines delimited by an empty line).
Parameters: text – The text to split into paragraphs (a string). Returns: A list of strings.
-
humanfriendly.text.tokenize(text)¶ Tokenize a text into numbers and strings.
Parameters: text – The text to tokenize (a string). Returns: A list of strings and/or numbers. This function is used to implement robust tokenization of user input in functions like
parse_size()andparse_timespan(). It automatically coerces integer and floating point numbers, ignores whitespace and knows how to separate numbers from strings even without whitespace. Some examples to make this more concrete:>>> from humanfriendly.text import tokenize >>> tokenize('42') [42] >>> tokenize('42MB') [42, 'MB'] >>> tokenize('42.5MB') [42.5, 'MB'] >>> tokenize('42.5 MB') [42.5, 'MB']
-
humanfriendly.text.trim_empty_lines(text)¶ Trim leading and trailing empty lines from the given text.
Parameters: text – The text to trim (a string). Returns: The trimmed text (a string).
humanfriendly.usage¶
Parsing and reformatting of usage messages.
The usage module parses and reformats usage messages:
- The
format_usage()function takes a usage message and inserts ANSI escape sequences that highlight items of special significance like command line options, meta variables, etc. The resulting usage message is (intended to be) easier to read on a terminal. - The
render_usage()function takes a usage message and rewrites it to reStructuredText suitable for inclusion in the documentation of a Python package. This provides a DRY solution to keeping a single authoritative definition of the usage message while making it easily available in documentation. As a cherry on the cake it’s not just a pre-formatted dump of the usage message but a nicely formatted reStructuredText fragment. - The remaining functions in this module support the two functions above.
Usage messages in general are free format of course, however the functions in
this module assume a certain structure from usage messages in order to
successfully parse and reformat them, refer to parse_usage() for
details.
-
humanfriendly.usage.USAGE_MARKER= 'Usage:'¶ The string that starts the first line of a usage message.
-
humanfriendly.usage.format_usage(usage_text)¶ Highlight special items in a usage message.
Parameters: usage_text – The usage message to process (a string). Returns: The usage message with special items highlighted. This function highlights the following special items:
- The initial line of the form “Usage: …”
- Short and long command line options
- Environment variables
- Meta variables (see
find_meta_variables())
All items are highlighted in the color defined by
HIGHLIGHT_COLOR.
-
humanfriendly.usage.find_meta_variables(usage_text)¶ Find the meta variables in the given usage message.
Parameters: usage_text – The usage message to parse (a string). Returns: A list of strings with any meta variables found in the usage message. When a command line option requires an argument, the convention is to format such options as
--option=ARG. The textARGin this example is the meta variable.
-
humanfriendly.usage.parse_usage(text)¶ Parse a usage message by inferring its structure (and making some assumptions :-).
Parameters: text – The usage message to parse (a string). Returns: A tuple of two lists: - A list of strings with the paragraphs of the usage message’s “introduction” (the paragraphs before the documentation of the supported command line options).
- A list of strings with pairs of command line options and their descriptions: Item zero is a line listing a supported command line option, item one is the description of that command line option, item two is a line listing another supported command line option, etc.
Usage messages in general are free format of course, however
parse_usage()assume a certain structure from usage messages in order to successfully parse them:The usage message starts with a line
Usage: ...that shows a symbolic representation of the way the program is to be invoked.After some free form text a line
Supported options:(surrounded by empty lines) precedes the documentation of the supported command line options.The command line options are documented as follows:
-v, --verbose Make more noise.
So all of the variants of the command line option are shown together on a separate line, followed by one or more paragraphs describing the option.
There are several other minor assumptions, but to be honest I’m not sure if anyone other than me is ever going to use this functionality, so for now I won’t list every intricate detail :-).
If you’re curious anyway, refer to the usage message of the humanfriendly package (defined in the
humanfriendly.climodule) and compare it with the usage message you see when you runhumanfriendly --helpand the generated usage message embedded in the readme.Feel free to request more detailed documentation if you’re interested in using the
humanfriendly.usagemodule outside of the little ecosystem of Python packages that I have been building over the past years.
-
humanfriendly.usage.render_usage(text)¶ Reformat a command line program’s usage message to reStructuredText.
Parameters: text – The plain text usage message (a string). Returns: The usage message rendered to reStructuredText (a string).
-
humanfriendly.usage.inject_usage(module_name)¶ Use cog to inject a usage message into a reStructuredText file.
Parameters: module_name – The name of the module whose __doc__attribute is the source of the usage message (a string).This simple wrapper around
render_usage()makes it very easy to inject a reformatted usage message into your documentation using cog. To use it you add a fragment like the following to your*.rstfile:.. [[[cog .. from humanfriendly.usage import inject_usage .. inject_usage('humanfriendly.cli') .. ]]] .. [[[end]]]
The lines in the fragment above are single line reStructuredText comments that are not copied to the output. Their purpose is to instruct cog where to inject the reformatted usage message. Once you’ve added these lines to your
*.rstfile, updating the rendered usage message becomes really simple thanks to cog:$ cog.py -r README.rst
This will inject or replace the rendered usage message in your
README.rstfile with an up to date copy.
-
humanfriendly.usage.import_module(name, package=None)¶ Import a module.
The ‘package’ argument is required when performing a relative import. It specifies the package to use as the anchor point from which to resolve the relative import to an absolute import.